常用ASCII码对照表,常用ascii码值
本作品内容为常用ASCII码对照表,格式为 doc ,大小 166440 KB ,页数为 12页
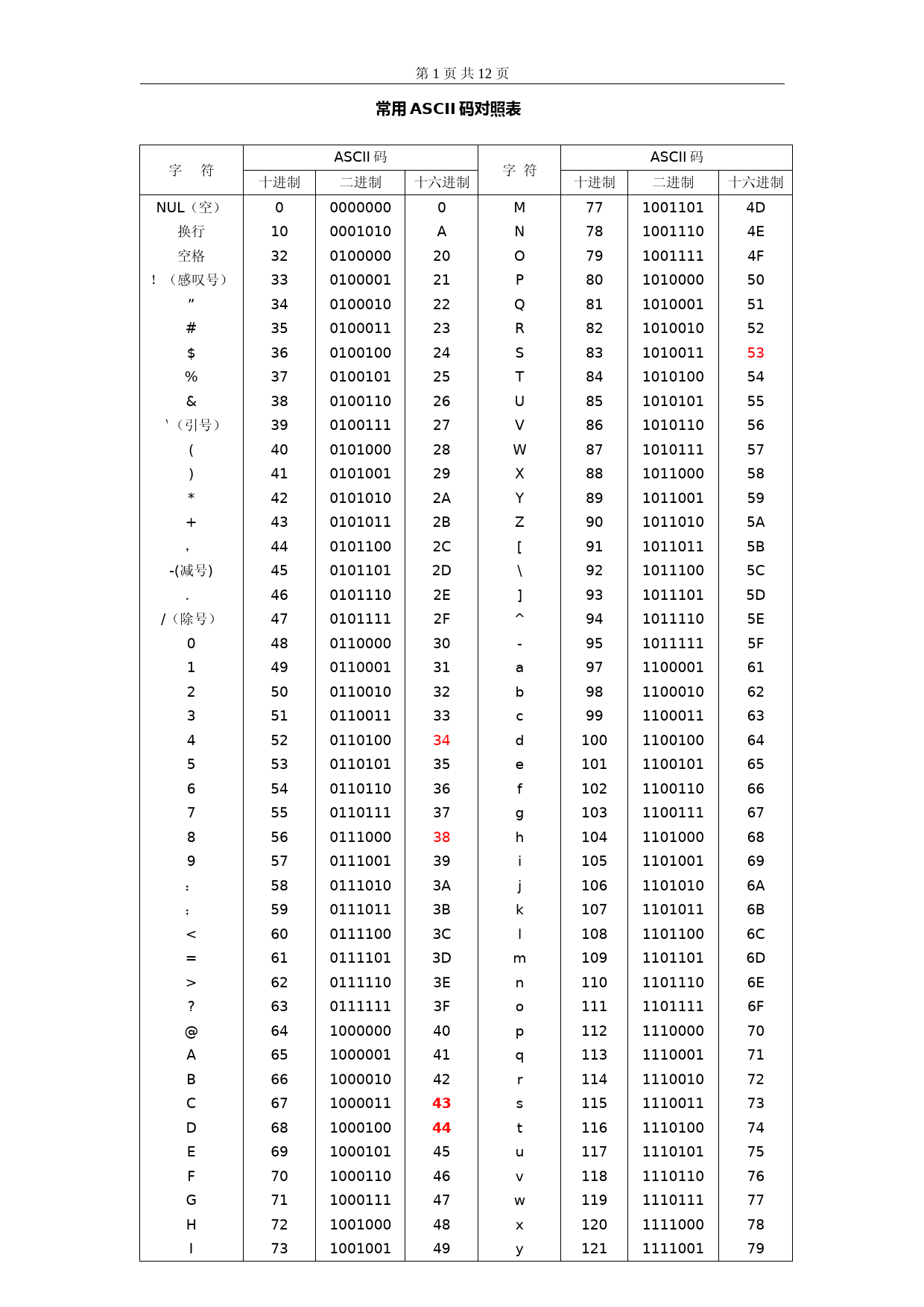
('第1页共12页常用ASCII码对照表字符ASCII码字符ASCII码十进制二进制十六进制十进制二进制十六进制NUL(空)换行空格!(感叹号)”#$%&`(引号)()+,-(减号)./(除号)0123456789:;<=>?@ABCDEFGHI010323334353637383940414243444546474849505152535455565758596061626364656667686970717273000000000010100100000010000101000100100011010010001001010100110010011101010000101001010101001010110101100010110101011100101111011000001100010110010011001101101000110101011011001101110111000011100101110100111011011110001111010111110011111110000001000001100001010000111000100100010110001101000111100100010010010A202122232425262728292A2B2C2D2E2F303132333435363738393A3B3C3D3E3F40414243444546474849MNOPQRSTUVWXYZ[\\]^-abcdefghijklmnopqrstuvwxy77787980818283848586878889909192939495979899100101102103104105106107108109110111112113114115116117118119120121100110110011101001111101000010100011010010101001110101001010101101011010101111011000101100110110101011011101110010111011011110101111111000011100010110001111001001100101110011011001111101000110100111010101101011110110011011011101110110111111100001110001111001011100111110100111010111101101110111111100011110014D4E4F505152535455565758595A5B5C5D5E5F6162636465666768696A6B6C6D6E6F70717273747576777879第2页共12页JKL7475761001010100101110011004A4B4Cz{}1221231251111010111101111111017A7B7D字符ASCII码字符ASCII码十进制二进制十六进制十进制二进制十六进制1.ASCII码在计算机内部,所有的信息最终都表示为一个二进制的字符串。每一个二进制位(bit)有0和1两种状态,因此八个二进制位就可以组合出256种状态,这被称为一个字节(byte)。也就是说,一个字节一共可以用来表示256种不同的状态,每一个状态对应一个符号,就是256个符号,从0000000到11111111。上个世纪60年代,美国制定了一套字符编码,对英语字符与二进制位之间的关系,做了统一规定。这被称为ASCII码,一直沿用至今。ASCII码一共规定了128个字符的编码,比如空格“SPACE”是32(十进制的32,用二进制表示就是00100000),大写的字母A是65(二进制01000001)。这128个符号(包括32个不能打印出来的控制符号),只占用了一个字节的后面7位,最前面的1位统一规定为0。2、非ASCII编码英语用128个符号编码就够了,但是用来表示其他语言,128个符号是不够的。比如,在法语中,字母上方有注音符号,它就无法用ASCII码表示。于是,一些欧洲国家就决定,利用字节中闲置的最高位编入新的符号。比如,法语中的é的编码为130(二进制10000010)。这样一来,这些欧洲国家使用的编码体系,可以表示最多256个符号。但是,这里又出现了新的问题。不同的国家有不同的字母,因此,哪怕它们都使用256个符号的编码方式,代表的字母却不一样。比如,130在法语编码中代表了é,在希伯来语编码中却代表了字母Gimel(ג),在俄语编码中又会代表另一个符号。但是不管怎样,所有这些编码方式中,0—127表示的符号是一样的,不一样的只是128—255的这一段。至于亚洲国家的文字,使用的符号就更多了,汉字就多达10万左右。一个字节只能表示256种符号,肯定是不够的,就必须使用多个字节表达一个符号。比如,简体中文常见的编码方式是GB2312,使用两个字节表示一个汉字,所以理论上最多可以表示256x256=65536个符号。3.Unicode正如上一节所说,世界上存在着多种编码方式,同一个二进制数字可以被解释成不同的符号。因此,要想打开一个文本文件,就必须知道它的编码方式,否则用错误的编码方式解读,就会出现乱码。为什么电子邮件常常出现乱码?就是因为发信人和收信人使用的编码方式不一样。解释:同一个文本文件,假设内容是用英语写的,在英语编码的情况下,每个字符会和一个二进制数对应(如00101000类似),然后存到计算机中,这时把这个英语文件发给一个俄语国家的用户,计算机传输的是二进制流,即0101之类的数据,到了俄语用户这方,需要有它的俄语编码方式进行解码,把每个二进制流转为字符显示,由于俄语编码表中对每串二进制流数据的解释方式不同,同一个数据如00101000在英语中可能代表A,而在俄语中则代表B,这样就会产生乱码,这是我个人的理解。第3页共12页GB2312编码、日文编码等也是非unicode编码,是要通过转换表(codepage)转换成unicode编码的,要不怎么显示出来呢?可以想象,如果有一种编码,将世界上所有的符号都纳入其中。每一个符号都给予一个独一无二的编码,那么乱码问题就会消失。这就是Unicode,就像它的名字都表示的,这是一种所有符号的编码。Unicode当然是一个很大的集合,现在的规模可以容纳100多万个符号。每个符号的编码都不一样,比如,U+0639表示阿拉伯字母Ain,U+0041表示英语的大写字母A,U+4E25表示汉字“严”。具体的符号对应表,可以查询unicode.org,或者专门的汉字对应表。4.Unicode的问题需要注意的是,Unicode只是一个符号集,只是一种规范、标准,它只规定了符号的二进制代码,却没有规定这个二进制代码应该如何存储在计算机上。比如,汉字“严”的unicode是十六进制数4E25,转换成二进制数足足有15位(100111000100101),也就是说这个符号的表示至少需要2个字节。表示其他更大的符号,可能需要3个字节或者4个字节,甚至更多。这里就有两个严重的问题,第一个问题是,如何才能区别unicode和ascii?计算机怎么知道三个字节表示一个符号,而不是分别表示三个符号呢?第二个问题是,我们已经知道,英文字母只用一个字节表示就够了,如果unicode统一规定,每个符号用三个或四个字节表示,那么每个英文字母前都必然有二到三个字节是0,这对于存储来说是极大的浪费,文本文件的大小会因此大出二三倍,这是无法接受的。它们造成的结果是:1)出现了unicode的多种存储方式,也就是说有许多种不同的二进制格式,可以用来表示unicode。2)unicode在很长一段时间内无法推广,直到互联网的出现。5.UTF-8互联网的普及,强烈要求出现一种统一的编码方式。UTF-8就是在互联网上使用最广的一种unicode的实现方式。其他实现方式还包括UTF-16和UTF-32,不过在互联网上基本不用。重复一遍,这里的关系是,UTF-8是Unicode的实现方式之一,它规定了字符如何在计算机中存储、传输等。UTF-8最大的一个特点,就是它是一种变长的编码方式。它可以使用1~4个字节表示一个符号,根据不同的符号而变化字节长度。UTF-8的编码规则很简单,只有二条:1)对于单字节的符号,字节的第一位设为0,后面7位为这个符号的unicode码。因此对于英语字母,UTF-8编码和ASCII码是相同的。2)对于n字节的符号(n>1),第一个字节的前n位都设为1,第n+1位设为0,后面字节的前两位一律设为10。剩下的没有提及的二进制位,全部为这个符号的unicode码。下表总结了编码规则,字母x表示可用编码的位。Unicode符号范围UTF-8编码方式(十六进制)(二进制)--------------------+---------------------------------------------第4页共12页00000000-0000007F0xxxxxxx00000080-000007FF110xxxxx10xxxxxx00000800-0000FFFF1110xxxx10xxxxxx10xxxxxx00010000-0010FFFF11110xxx10xxxxxx10xxxxxx10xxxxxx下面,还是以汉字“严”为例,演示如何实现UTF-8编码。已知“严”的unicode是4E25(100111000100101),根据上表,可以发现4E25处在第三行的范围内(00000800-0000FFFF),因此“严”的UTF-8编码需要三个字节,即格式是“1110xxxx10xxxxxx10xxxxxx”。然后,从“严”的最后一个二进制位开始,依次从后向前填入格式中的x,多出的位补0。这样就得到了,“严”的UTF-8编码是“111001001011100010100101”,这是保存在计算机中的实际数据,转换成十六进制就是E4B8A5,转成十六进制的目的为了便于阅读。6.Unicode与UTF-8之间的转换通过上一节的例子,可以看到“严”的Unicode码是4E25,UTF-8编码是E4B8A5,两者是不一样的。它们之间的转换可以通过程序实现。在Windows平台下,有一个最简单的转化方法,就是使用内置的记事本小程序Notepad.exe。打开文件后,点击“文件”菜单中的“另存为”命令,会跳出一个对话框,在最底部有一个“编码”的下拉条。里面有四个选项:ANSI,Unicode,Unicodebigendian和UTF-8。1)ANSI是默认的编码方式。对于英文文件是ASCII编码,对于简体中文文件是GB2312编码(只针对Windows简体中文版,如果是繁体中文版会采用Big5码)。2)Unicode编码指的是UCS-2编码方式,即直接用两个字节存入字符的Unicode码。这个选项用的littleendian格式。3)Unicodebigendian编码与上一个选项相对应。我在下一节会解释littleendian和bigendian的涵义。4)UTF-8编码,也就是上一节谈到的编码方法。选择完”编码方式“后,点击”保存“按钮,文件的编码方式就立刻转换好了。7.Littleendian和Bigendian第5页共12页上一节已经提到,Unicode码可以采用UCS-2格式直接存储。以汉字”严“为例,Unicode码是4E25,需要用两个字节存储,一个字节是4E,另一个字节是25。存储的时候,4E在前,25在后,就是Bigendian方式;25在前,4E在后,就是Littleendian方式。那么很自然的,就会出现一个问题:计算机怎么知道某一个文件到底采用哪一种方式编码?Unicode规范中定义,每一个文件的最前面分别加入一个表示编码顺序的字符,这个字符的名字叫做”零宽度非换行空格“(ZEROWIDTHNO-BREAKSPACE),用FEFF表示。这正好是两个字节,而且FF比FE大1。如果一个文本文件的头两个字节是FEFF,就表示该文件采用大头方式;如果头两个字节是FFFE,就表示该文件采用小头方式。8.实例下面,举一个实例。打开”记事本“程序Notepad.exe,新建一个文本文件,内容就是一个”严“字,依次采用ANSI,Unicode,Unicodebigendian和UTF-8编码方式保存。然后,用文本编辑软件UltraEdit中的”十六进制功能“,观察该文件的内部编码方式。1)ANSI:文件的编码就是两个字节“D1CF”,这正是“严”的GB2312编码,这也暗示GB2312是采用大头方式存储的。2)Unicode:编码是四个字节“FFFE254E”,其中“FFFE”表明是小头方式存储,真正的编码是4E25。3)Unicodebigendian:编码是四个字节“FEFF4E25”,其中“FEFF”表明是大头方式存储。4)UTF-8:编码是六个字节“EFBBBFE4B8A5”,前三个字节“EFBBBF”表示这是UTF-8编码,后三个“E4B8A5”就是“严”的具体编码,它的存储顺序与编码顺序是一致的。推荐这篇文章看一下:http://wiki.ubuntu.org.cn/index.php?title=Unicode&variant=zh-cn#.E8.B5.B7.E6.BA.90.E8.88.87.E7.99.BC.E5.B1.959.解决的问题:一、如何在中文系统中运行非Unicode编码程序?有很多意大利文版(除英文版)学习软件、百科全书等软件在中文系统上会出现乱码,解决方法:WindowsXP内核是Unicode编码,支持多语种,对于Unicode编码的应用程序会正常显示原文(因为windows核心是用unicode代码写的,所以不存在问题),但是,很多程序不是用Unicode编码写的,这时WindowsXP系统可以指定以特定的编码运行非Unicode编码程序,中文版WindowsXP默认的是“简体中文GB2312”。你只需在控制面板--〉区域和语言选项--〉高级--〉为非Unicode程序的语言选择“意大利语”,即可正确运行意大利文版的游戏程序。分析:我理解的流程是这样:程序------>意大利语编码(转换表codepage)------>解释成unicode识别的编码(通过指定的转换表将非Unicode的字符编码转换为同一字符对应的系统内部使用的Unicode编码)------>被系统翻译成意大利文(因为每个unicode编码对应了相应的意大利文字),便可以正常显示了。二、消除网页乱码?第6页共12页网页乱码是浏览器对HTML网页解释时形成的,如果网页制作时编码为繁体big5,浏览器却以编码gb2312显示该网页,就会出现乱码,因此只要你在浏览器中也以繁体big5显示该网页,就会消除乱码。打个比方有些像字典,繁体字得用繁体字典来查看,简体字得用简体字典来查看,不然你看不懂。【解决办法】:在浏览器中选择“编码”菜单,事先为浏览器安装多语言支持包(例如在安装IE时要安装多语言支持包),这样当浏览网页出现乱码时,即可手工更改查看此网页的编码方式,在浏览器中选择菜单栏下的“查看”/“编码”/“自动选择”/简体中文(GB2312),如为繁体中文则选择“查看”/“编码”/“自动选择”/繁体中文(BIG5),其他语言依此类推,便可消除网页乱码现象。分析:因为繁体big5编码后的文件,每个文字对应一个二进制流(假设是1212对应繁这个字),当我们以编码gb2312显示该网页时,gb2312编码会到表里去找1212(二进制流不会变的)对应谁,肯定不再是繁这个字了,当然显示的就不再是那个繁字了,也就会出现乱码了。这样理解简单些,其实中间还要转换成同一字符对应的系统内部使用的Unicode编码,然后通过系统底层unicode编码还原成相应字符显示出来。推荐两个编码查询网站:1.http://www.nengcha.com/code/ascii/2.http://bm.kdd.cc/ASCII非打印控制字符ASCII表上的数字0–31分配给了控制字符,用于控制像打印机等一些外围设备。例如,12代表换页/新页功能。此命令指示打印机跳到下一页的开头。ASCII非打印控制字符表十进制十六进制字符十进制十六进制字符000空1610数据链路转意101头标开始1711设备控制1202正文开始1812设备控制2303正文结束1913设备控制3404传输结束2014设备控制4505查询2115反确认606确认2216同步空闲707震铃2317传输块结束808backspace2418取消909水平制表符2519媒体结束100A换行/新行261A替换110B竖直制表符271B转意120C换页/新页281C文件分隔符130D回车291D组分隔符140E移出301E记录分隔符150F移入311F单元分隔符ASCII打印字符数字32–126分配给了能在键盘上找到的字符,当您查看或打印文档时就会出现。数字127代表DELETE命令。第7页共12页ASCII打印字符表十进制十六进制字符十进制十六进制字符3220space8050P3321!8151Q3422"8252R3523#8353S3624$8454T3725%8555U3826&8656V3927\'8757w4028(8858X4129)8959Y422A905AZ432B+915B[442C,925C\\452D-935D]462E.945E^472F/955F_483009660`493119761a503229862b513339963c5234410064d5335510165e5436610266f5537710367g5638810468h5739910569i583A:1066Aj593B;1076Bk603C<1086Cl第8页共12页613D=1096Dm623E>1106En633F?1116Fo6440@11270p6541A11371q6642B11472r6743C11573s6844D11674t6945E11775u7046F11876v7147G11977w7248H12078x7349I12179y744AJ1227Az754BK1237B{764CL1247C774DM1257D}784EN1267E~794FO1277FDEL扩展ASCII打印字符扩展的ASCII字符满足了对更多字符的需求。扩展的ASCII包含ASCII中已有的128个字符(数字0–32显示在下图中),又增加了128个字符,总共是256个。即使有了这些更多的字符,许多语言还是包含无法压缩到256个字符中的符号。因此,出现了一些ASCII的变体来囊括地区性字符和符号。例如,许多软件程序把ASCII表(又称作ISO8859-1)用于北美、西欧、澳大利亚和非洲的语言。第9页共12页扩展的ASCII打印字符表十进制十六进制字符十进制十六进制字符12880Ç192C0└12981ü193C1┴13082é194C2┬13183â195C3├13284ä196C4─13385à197C5┼13486å198C6╞13587ç199C7╟13688ê200C8╚13789ë201C9╔1388Aè202CA╩1398Bï203CB╦1408Cî204CC╠1418Dì205CD═1428EÄ206CE╬1438FÅ207CF╧14490É208D0╨14591æ209D1╤14692Æ210D2╥14793ô211D3╙14894ö212D4Ô第10页共12页14995ò213D5╒15096û214D6╓15197ù215D7╫15298ÿ216D8╪15399Ö217D9┘1549AÜ218DA┌1559B¢219DB█1569C£220DC▄1579D¥221DD▌1589E₧222DE▐1599Fƒ223DF▀160A0á224E0α161A1í225E1ß162A2ó226E2Γ163A3ú227E3π164A4ñ228E4Σ165A5Ñ229E5σ166A6ª230E6µ167A7º231E7τ168A8¿232E8Φ169A9⌐233E9Θ170AA¬234EAΩ171AB½235EBδ172AC¼236EC∞第11页共12页173AD¡237EDφ174AE«238EEε175AF»239EF∩176B0░240F0≡177B1▒241F1±178B2▓242F2≥179B3│243F3≤180B4┤244F4⌠181B5╡245F5⌡182B6╢246F6÷183B7╖247F7≈184B8╕248F8≈185B9╣249F9∙186BA║250FA·187BB╗251FB√188BC╝252FCⁿ189BD╜253FD²190BE╛254FE■191BF┐255FF10101010AA¬0001100018取消000011000C换页/新页10100110A6ª11001010CA╩11100101E5σ0101010054T第12页共12页001100013110101010155U010011004CL0010010125%0101001153S11000101C5┼0101010054T10110001B1▒0001000111设备控制1AAAA¬1818取消0C0C换页/新页A6A6ªCACA╩E5E5σ5454T313115555U4C4CL2525%1B1B转意0101头标开始',)
提供常用ASCII码对照表,常用ascii码值会员下载,编号:1700760197,格式为 docx,文件大小为12页,请使用软件:wps,office word 进行编辑,PPT模板中文字,图片,动画效果均可修改,PPT模板下载后图片无水印,更多精品PPT素材下载尽在某某PPT网。所有作品均是用户自行上传分享并拥有版权或使用权,仅供网友学习交流,未经上传用户书面授权,请勿作他用。若您的权利被侵害,请联系963098962@qq.com进行删除处理。

 下载
下载 下载
下载 下载
下载 下载
下载 下载
下载 下载
下载 下载
下载 下载
下载 下载
下载 下载
下载 下载
下载 下载
下载