传统协议栈和DPDK
本作品内容为传统协议栈和DPDK,格式为 docx ,大小 488093 KB ,页数为 10页
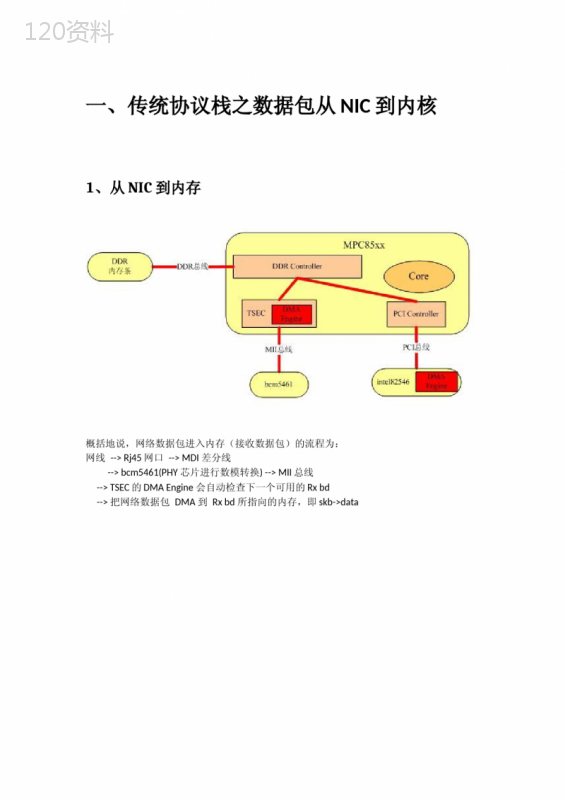
('一、传统协议栈之数据包从NIC到内核1、从NIC到内存概括地说,网络数据包进入内存(接收数据包)的流程为:网线-->Rj45网口-->MDI差分线-->bcm5461(PHY芯片进行数模转换)-->MII总线-->TSEC的DMAEngine会自动检查下一个可用的Rxbd-->把网络数据包DMA到Rxbd所指向的内存,即skb->data1、首先,内核在主内存中为收发数据建立一个环形的缓冲队列(通常叫DMA环形缓冲区)。2、内核将这个缓冲区通过DMA映射,把这个队列交给网卡;3、网卡收到数据,就直接放进这个环形缓冲区了——也就是直接放进主内存了;然后,向系统产生一个中断;4、内核收到这个中断,就取消DMA映射,这样,内核就直接从主内存中读取数据;对应以上4步,来看它的具体实现:1、分配环形DMA缓冲区Linux内核中,用skb来描述一个缓存,所谓分配,就是建立一定数量的skb,然后把它们组织成一个双向链表2、建立DMA映射内核通过调用dma_map_single(structdevicedev,voidbuffer,size_tsize,enumdma_data_directiondirection)建立映射关系。structdevicedev,描述一个设备;buffer:把哪个地址映射给设备;也就是某一个skb——要映射全部,当然是做一个双向链表的循环即可;size:缓存大小;direction:映射方向——谁传给谁:一般来说,是“双向”映射,数据在设备和内存之间双向流动;对于PCI设备而言(网卡一般是PCI的),通过另一个包裹函数pci_map_single,这样,就把buffer交给设备了!设备可以直接从里边读/取数据。3、这一步由硬件完成;4、取消映射ma_unmap_single,对PCI而言,大多调用它的包裹函数pci_unmap_single,不取消的话,缓存控制权还在设备手里,要调用它,把主动权掌握在CPU手里——因为我们已经接收到数据了,应该由CPU把数据交给上层网络栈;当然,不取消之前,通常要读一些状态位信息,诸如此类,一般是调用dma_sync_single_for_cpu()让CPU在取消映射前,就可以访问DMA缓冲区中的内容。2、从驱动到网络协议栈网络驱动收包大致有3种情况:noNAPI:mac每收到一个以太网包,都会产生一个接收中断给cpu,即完全靠中断方式来收包缺点是当网络流量很大时,cpu大部分时间都耗在了处理mac的中断。netpoll:在网络和I/O子系统尚不能完整可用时,模拟了来自指定设备的中断,即轮询收包。缺点是实时性差NAPI:采用中断+轮询的方式:mac收到一个包来后会产生接收中断,但是马上关闭。直到收够了netdev_max_backlog个包(默认300),或者收完mac上所有包后,才再打开接收中断通过sysctl来修改net.core.netdev_max_backlog或者通过proc修改/proc/sys/net/core/netdev_max_backlog以NAPI为例,NAPI相关数据结构每个网络设备(MAC层)都有自己的net_device数据结构,这个结构上有napi_struct。每当收到数据包时,网络设备驱动会把自己的napi_struct挂到CPU私有变量上。这样在软中断时,net_rx_action会遍历cpu私有变量的poll_list,执行上面所挂的napi_struct结构的poll钩子函数,将数据包从驱动传到网络协议栈。接收到一个完整的以太网数据包后,TSEC会根据eventmask触发一个Rx外部中断。cpu保存现场,根据中断向量,开始执行外部中断处理函数do_IRQ()do_IRQ伪代码{上半部处理硬中断查看中断源寄存器,得知是网络外设产生了外部中断执行网络设备的rx中断handler(设备不同,函数不同,但流程类似,TSEC是gfar_receive)1.mask掉rxevent,再来数据包就不会产生rx中断2.给napi_struct.state加上NAPI_STATE_SCHED状态3.挂网络设备自己的napi_struct结构到cpu私有变量_get_cpu_var(softnet_data).poll_list4.触发网络接收软中断下半部处理软中断依次执行所有软中断handler,包括timer,tasklet等等执行网络接收的软中断handlernet_rx_action1.遍历cpu私有变量_get_cpu_var(softnet_data).poll_list2.取出poll_list上面挂的napi_struct结构,执行钩子函数napi_struct.poll()(设备不同,钩子函数不同,流程类似,TSEC是gfar_poll)3.若poll钩子函数处理完所有包,则打开rxeventmask,再来数据包的话会产生rx中断4.调用napi_complete(napi_structn)把napi_struct结构从_get_cpu_var(softnet_data).poll_list上移走同时去掉napi_struct.state的NAPI_STATE_SCHED状态}gfar_process_frame()-->skb->protocol=eth_type_trans(skb,dev);//确定网络层包类型,IP、ARP、VLAN等等-->RECEIVE(skb)//调用netif_receive_skb(skb)进入协议栈进入函数netif_receive_skb()后,skb正式开始协议栈之旅。二、DPDK之数据包从NIC到应用程序DPDK是一套数据收发库。当一个数据包进入网卡产生中断后,响应这个中断的驱动是DPDK安装的驱动。这个驱动会通过UIO机制直接让用户态可以直接操作这个数据包。在用户态用户可以写一个程序通过DPDK提供的API处理这个数据包,比如直接在用户态写一个二层转发实现,或者在用户态直接实现一个vRouter等。1、网卡初始化网卡驱动模型一般包含三层,即,PCI总线设备、网卡设备以及网卡设备的私有数据结构,即将设备的共性一层层的抽象,PCI总线设备包含网卡设备,网卡设备又包含其私有数据结构。在DPDK中,首先会注册设备驱动,然后查找当前系统有哪些PCI设备,并通过PCI_ID为PCI设备找到对应的驱动,最后调用驱动初始化设备。一、网卡驱动注册使用attribute的constructor属性,在MAIN函数执行前,就执行rte_eal_driver_register()函数,将pmd_igb_drv驱动挂到全局dev_driver_list链表上。二、扫描当前系统有哪些PCI设备调用rte_eal_init()--->rte_eal_pci_init()函数,查找当前系统中有哪些网卡,分别是什么类型,并将它们挂到全局链表pci_device_list上。1、首先初始化全局链表pci_driver_list、pci_device_list。用于挂载PCI驱动及PCI设备。2、pci_scan()通过读取/sys/bus/pci/devices/目录下的信息,扫描当前系统的PCI设备,并初始化,并按照PCI地址从大到小的顺序挂在到pci_debice_list上。三、PCI驱动注册调用rte_eal_init()--->rte_eal_dev_init()函数,遍历dev_driver_list链表,执行网卡驱动对应的init的回调函数,注册PCI驱动。四、网卡初始化调用rte_eal_init()--->rte_eal_pci_probe()函数,遍历pci_device_list和pci_driver_list链表,根据PCI_ID,将pci_device与pci_driver绑定,并调用pci_driver的init回调函数rte_eth_dev_init(),初始化PCI设备。2、DPDK组件结构及功能DPDK是INTEL提供的提升数据面报文快速处理速率的应用程序开发包,它主要利用以下几个方面的支持特点来优化报文处理过程,从而加快报文处理速率:1、使用大页缓存支持来提高内存访问效率。2、利用UIO支持,提供应用空间下驱动程序的支持,也就是说网卡驱动是运行在用户空间的,减下了报文在用户空间和应用空间的多次拷贝。3、利用LINUX亲和性支持,把控制面线程及各个数据面线程绑定到不同的CPU核,节省了线程在各个CPU核来回调度。4、提供内存池和无锁环形缓存管理,加快内存访问效率。整个DPDK系统由许多不同组件组成,各组件为应用程序和其它组件提供调用接口,其结构图如下图所示:环境抽象层:为DPDK其它组件和应用程序提供一个屏蔽具体平台特性的统一接口,EAL提供的功能主要有:DPDK加载和启动;支持多核或多线程执行类型;CPU核亲和性处理;原子操作和锁操作接口;时钟参考;PCI总线访问接口;跟踪和调试接口;CPU特性采集接口;中断和告警接口等。2、堆内存管理组件(Malloclib):堆内存管理组件为应用程序提供从大页内存分配堆内存的接口。当需要分配大量内存小块时(如用于存储列表中每个表项指针的内存),使用这些接口可以减少TLB缺页。3、环缓冲区管理组件:环缓冲区管理组件为应用程序和其它组件提供一个无锁的多生产者多消费者FIFO队列API。4、内存池管理组件:为应用程序和其它组件提供分配内存池的接口,内存池是一个由固定大小的多个内存块组成的内存容器,可用于存储相同对像实体,如报文缓存块等。内存池由内存池的名称(一个字符串)来唯一标识,它由一个环缓中区和一组核本地缓存队列组成,每个核从自已的缓存队列分配内存块,当本地缓存队列减少到一定程度时,从内存环缓冲区中申请内存块来补充本地队列。5、网络报文缓存块管理组件:提供应用程序创建和释放用于存储报文信息的缓存块的接口,这些MBUF存储在一内存池中。提供两种类型的MBUF,一种用于存储一般信息,一种用于存储报文数据。6、定时器组件:提供一些异步周期执行的接口(也可以只执行一次),可以指定某个函数在规定的时间异步的执行,就像LIBC中的timer定时器,但是这里的定时器需要应用程序在主循环中周期调用rte_timer_manage来使定时器得到执行,使用起来没有那么方便。定时器组件的时间参考来自EAL层提供的时间接口。除了以上六个核心组件外,DPDK还提供以下功能:1、以太网轮询模式驱动(PMD)架构:把以太网驱动从内核移到应用层,采用同步轮询机制而不是内核态的异步中断机制来提高报文的接收和发送效率。2、报文转发算法支持:Hash库和LPM库为报文转发算法提供支持。3、网络协议定义和相关宏定义:基于FreeBSDIP协议栈的相关定义如:TCP、UDP、SCTP等协议头定义。4、报文QOS调度库:支持随机早检测、流量整形、严格优先级和加权随机循环优先级调度等相关QOS功能。5、内核网络接口库(KNI):提供一种DPDK应用程序与内核协议栈的通信的方法,类似普通LINUX的TUN/TAP接口,但比TUN/TAP接口效率高。每个物理网口可以虚拟出多个KNI接口。三、一些概念1、PCIPeripheralComponentInterconnect(外设部件互连标准)的缩写,它是目前个人电脑中使用最为广泛的接口,几乎所有的主板产品上都带有这种插槽。2、MII即媒体独立接口,也叫介质无关接口。它是IEEE-802.3定义的以太网行业标准。它包括一个数据接口,以及一个MAC和PHY之间的管理接口(图1)。数据接口包括分别用于发送器和接收器的两条独立信道。每条信道都有自己的数据、时钟和控制信号。MII数据接口总共需16个信号。管理接口是个双信号接口:一个是时钟信号,另一个是数据信号。通过管理接口,上层能监视和控制PHY以太网媒体接入控制器(MAC)和物理接口收发器(PHY)3、中断从本质上来讲,中断是一种电信号,当设备有某种事件发生时,它就会产生中断,通过总线把电信号发送给中断控制器。如果中断的线是激活的,中断控制器就把电信号发送给处理器的某个特定引脚。处理器于是立即停止自己正在做的事,跳到中断处理程序的入口点,进行中断处理(1)硬中断由与系统相连的外设(比如网卡、硬盘)自动产生的。主要是用来通知操作系统系统外设状态的变化。比如当网卡收到数据包的时候,就会发出一个中断。我们通常所说的中断指的是硬中断(hardirq)。(2)软中断为了满足实时系统的要求,中断处理应该是越快越好。linux为了实现这个特点,当中断发生的时候,硬中断处理那些短时间就可以完成的工作,而将那些处理事件比较长的工作,放到中断之后来完成,也就是软中断(softirq)来完成。软中断是执行中断指令产生的,而硬中断是由外设引发的。硬中断的中断号是由中断控制器提供的,软中断的中断号由指令直接指出,无需使用中断控制器。硬中断处理程序要确保它能快速地完成任务,这样程序执行时才不会等待较长时间,称为上半部。软中断处理硬中断未完成的工作,是一种推后执行的机制,属于下半部。4、一致性DMAdma_alloc_coherent(dev,size,&dma_handle,gfp);流式DMAdma_map_single(dev,addr,size,direction);dma_unmap_single(dev,dma_handle,size,direction);一致性DMA可以认为是“同步的”,就是DMA和CPU之间看到的物理内存是一致的。流式DMA则不然。DMA操作和CPU之间的主要隔阂就是cache,因为一般来说DMA只操作物理内存,不会动cache,但CPU却首先看到的是L1L2cache,所以设备驱动就需要调用正确的DMA函数来操作cache。拿网卡收发包为例,假如CPU发包给网卡,那CPU填好skb的数据之后,得先把cache里有关这个skb数据的行给刷到物理内存,否则网卡从物理内存拿到的数据不是真正所要的数据。反之,CPU把skb数据装配好DMArxdescriptor的时候,得先invalid掉这个skb数据在cache里的行。这样DMA把收到的包填到物理内存后再中断告知CPU时,CPU就可以避免从cache拿到关于这个skb的老(脏)数据,而会从物理内存取包而重新建立数据cache。dma_map_singledma_unmap_single做的就是这个事情,它会根据数据的方向来判断该是cleancache还是incalidcache。那么DMA描述符呢,DMA控制器和CPU都要对DMA描述符做频繁操作,当CPU和DMA需要频繁的操作一块内存区域的时候,一致性DMA映射就比较合适。所以DMA描述符特别适用于一致性DMA。当然,你也可以对DMA描述符用流式操作,但那样开销就比较大了。',)
提供传统协议栈和DPDK会员下载,编号:1700675225,格式为 docx,文件大小为10页,请使用软件:wps,office word 进行编辑,PPT模板中文字,图片,动画效果均可修改,PPT模板下载后图片无水印,更多精品PPT素材下载尽在某某PPT网。所有作品均是用户自行上传分享并拥有版权或使用权,仅供网友学习交流,未经上传用户书面授权,请勿作他用。若您的权利被侵害,请联系963098962@qq.com进行删除处理。

 下载
下载 下载
下载 下载
下载 下载
下载 下载
下载 下载
下载 下载
下载 下载
下载 下载
下载 下载
下载 下载
下载 下载
下载