Lwip,lwip
本作品内容为Lwip,格式为 doc ,大小 363520 KB ,页数为 18页
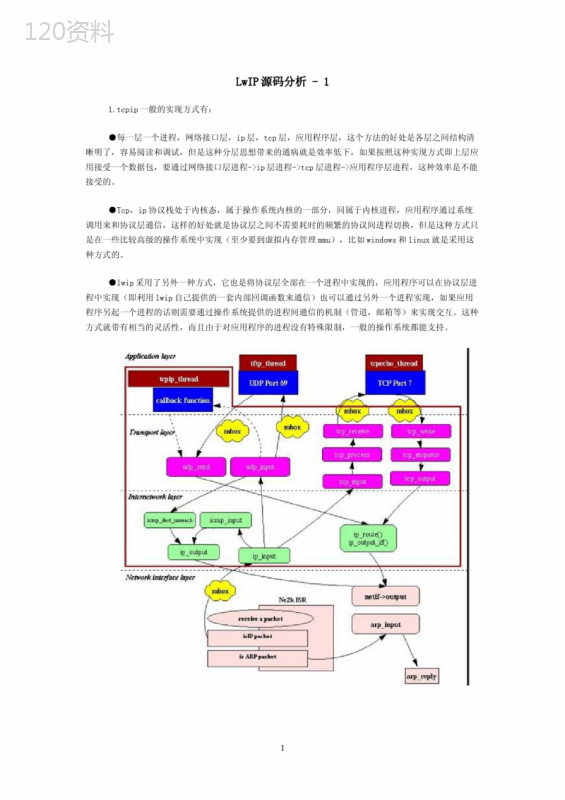
('LwIP源码分析-11.tcpip一般的实现方式有:●每一层一个进程,网络接口层,ip层,tcp层,应用程序层,这个方法的好处是各层之间结构清晰明了,容易阅读和调试,但是这种分层思想带来的通病就是效率低下,如果按照这种实现方式即上层应用接受一个数据包,要通过网络接口层进程->ip层进程->tcp层进程->应用程序层进程,这种效率是不能接受的。●Tcp,ip协议栈处于内核态,属于操作系统内核的一部分,同属于内核进程,应用程序通过系统调用来和协议层通信,这样的好处就是协议层之间不需要耗时的频繁的协议间进程切换,但是这种方式只是在一些比较高级的操作系统中实现(至少要到虚拟内存管理mmu),比如windows和linux就是采用这种方式的。●lwip采用了另外一种方式,它也是将协议层全部在一个进程中实现的,应用程序可以在协议层进程中实现(即利用lwip自己提供的一套内部回调函数来通信)也可以通过另外一个进程实现,如果应用程序另起一个进程的话则需要通过操作系统提供的进程间通信的机制(管道,邮箱等)来实现交互。这种方式就带有相当的灵活性,而且由于对应用程序的进程没有特殊限制,一般的操作系统都能支持。1整个学习的过程也打算按照这种流程来学习,先从底层看起(这部分也是我最熟悉的),依次从networkintecelayer->internetworklayer->transportlayer->applicationlayer(这也是按照tcpip的经典四层分法的)。首先来看网络接口层:这一层的主要文件位于/src/netif目录,主要是网络设备驱动文件(一个skeleton程序),一个loopback文件(非常简单),arp模块,ppp协议栈。核心的netif的通用程序在/src/core目录下。1.重要的结构体有:Structnetif{……}这个结构体相当linux中的net_device结构体,用lwip的原文来说就是整个网络接口层中都会用到的一个结构体,对于理解这一层非常重要。2具体看一下:structnetif{/指向链表中下一个网络接口的指针structnetifnext;/IPaddressconfigurationinnetworkbyteorderstructip_addrip_addr;structip_addrnetmask;structip_addrgw;/这个函数是设备驱动调用用来向tcpip协议层传递数据包/err_t(input)(structpbufp,structnetifinp);/这个函数是当ip层想向网络接口层发送一个数据包时调用,一般会先将ip地址解析为mac地址,然后发送err_t(output)(structnetifnetif,structpbufp,structip_addripaddr);/这个函数是当arp模块需要向接口层发送数据包时被调用,err_t(linkoutput)(structnetifnetif,structpbufp);……/用来指向设备的独有的一些信息,类似linux中常用的voidprivate.voidstate;#ifLWIP_DHCP/这个netif的dhcp信息structdhcpdhcp;#endif/LWIP_DHCP#ifLWIP_AUTOIP/theAutoIPclientstateinformationforthisnetifstructautoipautoip;#endif#ifLWIP_NETIF_HOSTNAME/thehostnameforthisnetif,NULLisavalidvaluecharhostname;#endif/LWIP_NETIF_HOSTNAME/最大传送字节数,以太网一般是1500个字节(术语应该叫八位组)u16_tmtu;/硬件地址长度,对于以太网就是mac地址长度,一般为6个字节u8_thwaddr_len;/mac地址u8_thwaddr[NETIF_MAX_HWADDR_LEN];/flags(seeNETIF_FLAG_above)3u8_tflags;/descriptiveabbreviationcharname[2];/numberofthisinteceu8_tnum;……#ifLWIP_IGMP/这个函数在添加或者删除mac地址的多播路由表时被调用/err_t(igmp_mac_filter)(structnetifnetif,structip_addrgroup,u8_taction);#endif/LWIP_IGMP#ifLWIP_NETIF_HWADDRHINTu8_taddr_hint;#endif/LWIP_NETIF_HWADDRHINT#ifENABLE_LOOPBACK/Listofpacketstobequeuedforourselves.structpbufloop_first;structpbufloop_last;#ifLWIP_LOOPBACK_MAX_PBUFSu16_tloop_cnt_current;#endif/LWIP_LOOPBACK_MAX_PBUFS#endif/ENABLE_LOOPBACK};LwIP源码分析-2从功能上来说,arp可以简单的分成两个部分:4a.当我要向目的ip发送一个数据包的时候,需要通过arp实现ip到物理地址(一般为mac地址)的映射->ethernet_output函数b.处理输入包,更新arp缓存,如果是ip包后递交给ip层,如果是arp包,对于不同的arp操作做相应的相应->etharp_input函数。ethernet_input函数:以太网的帧类型可以是:IP,ARP甚至可以是pppoe,wlan等。这里主要分为IP,ARP(注意:iparp在以太网的帧类型中是并列的,所以在input这个函数中分为ip,arp两大部分)对于ip类型的:主要工作就是看是否开启了ETHARP_TRUST_IP_MAC这个选项,如果开启了就是要用这个帧中的信息来更新arp缓冲(利用帧首部的源mac地址和帧数据中ip报文中的源ip地址),然后丢弃以太网帧首部传递给ip层(即ip_input)。对于arp类型的:同样先更新arp缓存,然后判断arp报文的操作类型,在lwip中对于arp数据包实现了两种操作:(rarp请求,rarp响应已经几乎淘汰了)a.arp请求:首先判断这个包是不是给本机的,如果是给本机的,在原有包的基础上重组一个回应包并发出(注意此处并没有重新分配一个pbuf,而是借用了原来的缓冲结构)。如果不是本机的忽略。b.arp回应:主要的工作是更新arp缓存,但是这一步已经在arp包刚进来的时候就处理了,所以这里不需要再重复做,这里有一些dhcp的东东,暂时还未涉及到。这里无论是ip类型,还是arp类型,都会更新arp缓存,也就是我们的update_arp_entry(structnetifnetif,structip_addripaddr,structeth_addrethaddr,u8_tflags),其中netif是对应的网络接口,ipaddr和ethaddr分别是对应的ip地址和mac地址。这个函数中会去更新arp缓存,并且把这个arp表项的等待的队列通过发送函数发送出去()。update_arp_entry:先通过调用find_entry找到对应ipaddr对应的表项——>设置相应的arp选项的成员(主要是state,netif,ethaddr,cttime)——>如果定义了arp_queue的话,并且这个arp表项上有未发送队列的话,把这些队列发送出去。其中find_entry这个函数蛮重要的,下面解释下这个函数的流程。find_entry:1.lwip有一个比较巧妙的地方,它并不是冲上去就是就把arp缓存中所有的表项搜索一遍,而是做了一5个假设,假设这次的表项索引还是上一次的,ifso,wearereallyfast!(因为在很多情况下就是这样的)2.首先搜索分成三类,empty,suspending,stable。第一个是对状态为empty的检查,arp表项中第一个状态为empty的索引号,第二个对状态为suspend的检查,分成三部分,首先判断是否恰好为此次想要的ip对应的索引,如果是直接返回;不是的话又分这个索引是有queue还是没有queue,分别记录这两种类型中cttime最大的一个索引,第三个是对状态为stable的检查,分成两部分,首先判断是否恰好为此次想要的ip对应的索引,如果是直接返回;不是的话,记录状态为stable中cttime最大的(时间戳,最老的)。因此这部分,主要做了两件事:●如果arp缓存中有现成的索引,则直接返回(状态时suspend和stable);●通过索引记录几个重要的参数:a.arp表项中第一个状态为empty的索引号b.arp表项中最老的状态为suspend的有queue的索引号c.arp表项中最老的状态为suspend的没有queue的索引号d.arp表项中最老的状态为stable的索引号。这些参数是在arp缓存没有现成索引号时,会根据优先级来对这四个参数来选择或删除表项。优先级等级依次为:empty——》oldeststable——》oldestpendingwithoutqueue——》oldestpendingwithqueue3.arp没有现存的缓存,而状态又不是empty的选项,意味着需要在里面删除现有的arp选项,这里则需要调用snmp_delete,由于snmp的东东暂时还未看到,这里就不详细讲了。4.最后更新表项的一些成员,有状态,时间戳,索引缓存ethernet_output函数:由于是发送ip数据包,所以一开始需要增加缓冲区大小,大小为以太网的数据首部的大小。然后检查ip地址,可以分为广播包,多播包,单播包(单播包又分为是局域网内部还是局域网外面)广播包:判断目的ip地址是不是为全1,或者是全0(老版本中使用的),如果是广播包则目的ip的mac地址不需要查询arp缓存或者发送arprequest,mac地址为全一,即0xff,0xff,0xff,0xff,0xff,0xff。多播包:判断目的ip地址是不是d类地址,即eXXXX,如果是多播的话,mac地址也是确定的,即将ip地址的低23位映射到mac地址为01-00-5e-00-00-00的低23位上。单播包:要比较目的ip和本地ip地址,看是否是局域网内的,不是局域网内的,则调用默认网关的地址,然后再统一调用etharp_query(netif,ipaddr,q);函数而广播包和多播包则无需调用etharp_query(netif,ipaddr,q);函数,因为已经得到了明确的mac地址,基本只需要添加以太网帧首部然后发送即可。etharp_query:大概流程如下:a.先通过ipaddr利用函数find_entry找到arp缓存中的索引号b.根据索引号就能得到arp的对应项,此时根据项的state分成三大类,empty:说明原来表项中是没有这个arp缓存的,所以把表项状态切换为pending并发送arp_requst包,把待发送的数据放在这个entry(表项)的队列上,系统在input的时候解析了这个ip后会发送(具体可以看前面input中的讲解);pending:说明这个ip原来就有了,我们再重新发一次arp_request,同样把待发送数据放在队列上;stable:说明在arp缓存中ip地址已经有了解析的mac地址,此时又分成两类,一类是数据包不为空,则直接调用etharp_send_ip函数发送;第二类是如果数据包为空,则说明是一个request包,还是调用arp_request6LwIP源码分析-3摘要:在内存需求分析的基础上,阐述了LwIPTCP/IP协议栈中pbuf结构的基本原理和内存管理机制的实现。这对在嵌入式系统中实现TCP/IP协议栈,进行网络连接有重要意义。关键词:TCP/IP协议LwIP协议栈内存管理pbuf结构目前,在嵌入式系统中引入TCP/IP协议栈及将嵌入式设备接入网络,已经成为嵌入式领域重要的发展方向。TCP/IP是一种基于OSI参考模型的分层网络体丆系结构,它由应用层、运输层、网络层、数据链路层、物理层组成。各层之间消息的传递通过数据报的形式进行。由于各层之间报头长度不一样。当数据在不同协议层之间传递时.对数据进行封装和去封装、增丆加和删除操作将十分频繁。在嵌入式系统开发中也经常遇到类似问题。用户数据从本地嵌入式设备传输到远程主机的过程中,要经过各层协议,对消息的封装、去封装和拷贝操作几乎是不可避免的。而通常所采用的用一段连续的内存区来存储、传递数据的做法丆会有以下的缺陷:(1)当从上层向下层传递数据时,下层协议需要对数据进行封装,而上层在申请内存时没有(也不应该)考虑下层的需要。这样会导致下层协议处理时需要重新申请内存并进行内存拷贝,从而影响程序的效率。(2)当从下层向上层传递数据时,下层协议专有的数据结构应当对上层协议不可见。因此也需要重新7申请内存并进行内存拷贝。(3)随着数据的逐层处理,其内容可能有所增减,而连续内存很难处理这种动态的数据增删。0因此,必须有一种能适应数据动态增删、但在逻辑上又呈现连续性的数据结构,以满足在各协议层之间传递数据而不需要进行内存拷贝。嵌入式TCP/IP协议栈要求简单高效,并减少对内存的需求。这些都需要相应的内存管理机制实现。1LwIP协议栈中pbuf介绍LwIP(LightweightIP)是瑞士计算机科学院AdamDunkels等开发的一套用于嵌入式系统的开放源代码TCP/IP协议栈。LwlP可以移植到操作系统上,也可以在无操作系统的情况下独丆立运行。LwIPTCP/IP实现的重点是:在保持TCP协议主要功能的基础上,减少对RAM的占用。这使LwIP协议栈适合在低端嵌入式系统中使用。LwIP利丆用pbuf结构实现数据传递,它与BSD中的Mbuf很相似。pbuf的主要用途是保存在应用程序和同络接口间互相传递的用户数据。2LwIP内存管理的实现在运行TCT/IP协议栈的嵌入式系统中。可以把整个系统的存储区域分为协议栈管理的存储器和应用程序管理的存储器两部分。2.1协议栈管理的存储器协议栈管理的存储器是指TCP/IP内核能够操作的内存区域,主要用于装载待接收和发送的网络数据分组。当接收到分组或者有分组要发送时,TCP/IP协议栈为这些分组分配缓存;接收到的分组交付给应用程序或者分组已经发送完毕后,对分配的缓存回收重用。协议栈分配的缓存必须能容纳各种大小的报文,例如从仅仅几个字节的ICMP回答报文到几百个字节的TCP分段报文。LwIP中的pbuf有四种类型:PBuF_POOL、PBUF__RAM、PBUF_ROM、PBUF_REF。这四种类型的pbuf都是从TCP/IP协议栈管理的存储器中分配的,其中PBUF_ROM和PBUF_REF与应用程序管理的存储区域密切相关。PBUF_POOL是具有固定容量的pbuf,主要供网络设备驱动使用,为收到的数据分组分配缓存。在协议栈管理的内存中初始化了一个pbuf池(PBUF_P00L),具有相同尺寸的pbuf都是从这个pbuf池中分配得到。一般使用多个PBUF_POOL链接成一个链表,用于存储数据分组。如图1所示。LwIP用一个宏定义一个PBUF_P00L的大小。一个分组需要分配几个PBUF_POOL,而在数据较少时分配一个PBUF_POOL即可。由于分配一个PBUF_P00L类型的pbuf很快,适合在中断处理中使用,所以PBUF_POOL主要供网络设备驱动使用,为收到的数据分组分配缓存。应用程序发送动态产生的数据时.可以用PBUF_RAM类型的pbuf。PBUF_RAM在事先划分好的内存堆中分配。对该内存堆的操作类似于C语言中的malloc/free。内存堆分配的结构如图2所示。图2中每个被分配的存储块附带了一个小结构,该结构的两个指针指向相邻的内存块。used标识位用来指示该内存块的分配情况,阴影部分表示已经被分配了,此时used为1。当需要一块N字节的存储块时,就对整个存储堆进行搜索。如果找到一块未用的(used=O)并且容量不小于N字节的区域就表示分配成功,并且置used为1。而分配的内存块使用完后需要释放,为了不产生碎片,相邻且未用的内存块需要进行合并。PBUF_P00L和PBUF_RAM都可以根据需要从存储器中动态分配,这种分配机制又称为动态存储器分配机制。该分配机制不仅能为应用程序的数据分配存储空间,而且能为协议首部分配存储空间。在层与层之间传递数据时,真正需要修改的只是数据的格式,使之符合各层的规范,而数据本身不需要变动。实际上数据格式反应的是各层的首部,当数据在各层之间传送时,需要动态地添加和移去相应的首部,用动态分配机制可以很好地实现。2.2应用程序管理的存储器应用程序管理的存储器是指应用程序管理、操作的存储区域.一般从该区域为应用程序发送数据分配缓存。虽然该存储区域不由TCP/IP协议栈管理,但在不严格分层的协议栈中,该存储区域必须与TCP/IP管理的存储器协同工作。为节省内存,LwIP不采取分级访问模式,而是通过指针访问数据。这样就不需要8为数据的传递分配存储空间。应用程序发送的数据在交付LwIP后,LwIP就认为这些数据是不能被改动的,因此应用程序的数据被认为是永远存在并且不能被改变的。这一点与ROM很相似.类型名PBUF_ROM也由此而来。如图3所示,PBUF_ROM的数据指针payload指向Externalmemory(外部存储区)。Extemalmemory指不由TCP/IP协议栈管理的存储区,它可以是应用程序管理的存储器为用户数据分配的缓存,也可以是ROM区域,如静态网页中的字符串常量等。由于由应用程序交付的数据不能被改动,因此就需要动态地分配一个PBUF_RAM来装载协议的首部,然后将PBUF_RAM(首部)添加到PBUF_ROM(数据)的前面。这样就构成了一个完整的数据分组。图3中的PBUF_ROM还可以是PBUF_REF。PBUF_REF和PBUF_ROM的特性非常相似,都可以实现数据的零拷贝。但是当发送的数据需要排队时就表现出PBUF_REF的特性了。例如在发送分组时,待发送的分组需要在ARP队列中排队,假如这些分组中有PBUF_ROM类型的pbuf,则说明该类型pbuf中的数据位于应用程序的存储区域,是通过指针被PBUF_ROM引用的。这样直到分组被处理之前,被引用的应用程序的这块存储区域都不能另作它用。在此情况下要用到PBUF_REF类型的pbuf。在排队时,LwIP会为PBUF_REF类型的pbuf分配缓存(PBUF_POOL或PBUF_RAM),并将引用的应用程序的数据拷贝到分配的缓存中。这样应用程序中被引用数据的存储区域就能被释放。pbuf结构实现了层与层之间的数据传递,但其非常消耗内存,并且需要TCP/IP协议栈为之分配存储空间,例如协议控丆制udp_pcb、tep_pcb等。通常,嵌入式TCP/IP协议栈都不是严格分层的,尽量减少对内存的需求是实现嵌入式TCP/IP的重点,内核的内存管理机制直接关系到嵌入式TCP/IP协议栈的性能。9LwIP源码分析-4IP层(先主要研究ipv4)简述:Ip层的目的有三个:a.ip层定义了在整个tcpip互联网中使用的数据传送基本单元,其他的高级协议都是放在ip层的数据区的。(ICMP,IGMP(这两个仍然属于ip协议的一部分),UDP(DHCP使用UDP来携带),TCP均是这样)效果图如下:b.ip层软件完成转发的功能,选择分组发送的路径。因为ip层是实现一个ip到另外一个ip之间的通路,网路的概念在这一层已经被它屏蔽,所以它要完成ip包路径的选择。c.ip还体现了不可靠分组交付思路的规则。这些规则包括如何处理分组,如何产生差错报文(ICMP)。1.ipinput:ip这一层还是相对比较简单的,毕竟是不可靠分组的,只是在ip的分片和重装部分还是有点小烦的。看一下具体流程:从网络接口层到达的数据包,一般数据指针已经移到了ip首部的位置了,这一步是在arp_input的pbuf_header(p,-(s16_t)SIZEOF_ETH_HDR)实现了。因此在ipinput的开始获取ip数据首部的一些信息,10比如首部长度,数据包总长度,核对校验和等等。调用pbuf_realloc(p,iphdr_len);,其实这部一般没多少意思。接下来是关于DHCP的一些处理,暂时打算不涉及这部分(等把tcpip的路全部走通了一遍再来看这些features)。如果netif不是针对本网卡,则调用ip_forward转发到其他网络接口上。最后判断ip首部的协议类型:a.如果是UDP,则调用udp_input,将数据提交到传输层b.如果是TCP,则调用tcp_input,将数据提交到传输层c.如果是ICMP,则调用icmp_input,将数据提交到icmp模块处理,一般来说icmp是属于ip层的一部分的,虽然它的报文封装形式和tcp/udp类似,都是封装在ip数据区。d.如果是IGMP,与ICMP类似,我们认为igmp是ip协议的一部分。提交给IGMP模块处理。2.ipoutput:\uf0e0ip层的output函数还是比较简单的,主要的工作就是填充ip的数据首部,然后调用netif的output函数(一般是etharp_output---netif的linkoutput)。下面是流水账:ip_route寻找合适的网络设备,对于多个网络接口有用——》ip_output_if真正的发送函数——》接下来就是添加ip数据首部(分成已经有ip首部和没有ip首部两种情况)——》lwip1.3.2还增加了对数据包分片和重装的支持,接下来就是判断是否支持分片,支持的话调用Ip_frag函数——》最终调用netif->output函数发送ip数据包。So,ip层还遗留一些问题:icmp的问题,igmp的问题,分片和重装。11LwIP源码分析-5UDP层:看了这么久的网络协议代码,发现在这几层的处理大同小异,主要就是对数据包协议处理,一层层剥离、判断,分析,辨别,因为即使到了udp层依旧是不可靠的无连接的交付服务,所以在udp这一层的代码还是相对比较简单的。先说一下udp层的几个特点:1.ip层其实是处理了网络中一台主机到另外一台主机之间的通信,而udp则更深入一步,它通过利用端口的概念处理了一个应用程序到另外一个应用程序之间的通信,因此udp的通信需要两个参数:目的ip地址,协议端口号。2.由于ip协议的checksum只是对ip数据首部,并不对ip数据区的,所以在udp部分还需要一次校验和。而udp校验和的计算部分除了udp数据报本身还有ip地址,ip协议等(因为udp首部仅仅指明了端口号,但是要正确验证一个udp通信,还需要知道ip地址),因此引入了udp伪首部的概念。也正是因为伪首部的校验的原因,会发现在lwip对数据帧头部移动的处理对于udp这一层有特殊处理,在之前的几层都是在进入下一层之前已经把本层的数据首部去除,而在ip层并没有移动ip的首部指针,而是到了udp层再动的(tcp层也应该如此),因为udp(tcp)层还需要ip首部的一些信息。3.对于checksum范围的不同,产生了一个udp的变异udp_lite,具体可以参见这篇文章http://blog.chinaunix.net/u3/99423/showart_2148628.html,主要的目的就是在一些网络差错率比较大,但是应用对轻微差错不敏感的应用中,典型的就是在线视频。毕竟因为一位错误就丢失整个udp数据包对于这种应用来说代价太大,也没有意义。Udp_lite可以指定校验多少范围,但是至少超过8个字节(也就是udp首部是一定要被checksum的),长度为0时表明校验整个udp数据包。8>length>0认为是一个非法值。4.udp对于ip层多了端口的概念,对于一个应用一定有具有一个端口号,tcpip协议中使用了一种叫混合端口分配的方法(兼具了统一分配和动态绑定),即把低端口号分配给一些通用的协议和应用,把比较大的整数留给动态分配。因此在lwip中除了在其他层中常见的input,output函数外,还有一个bind函数。Udp_input:不想再啰嗦说一大堆废话了,与之前不同的是,这里有一个udp_pcb的会话链表,每一个UDP话路(session)的状态都被保留在一个PCB结构中,如图7所示。UDPPCBs保存在一个链表中,当UDPdatagram到达,则搜索该链表并进行匹配。UDPPCB结构中包含一个指向全局UDPPCB链表中的下一个PCB的指针。UDP话路(session)由IP地址和端口号来定义,并且被存放在local_ip,dest_ip,local_port,dest_port域中。Flags域指出这一话路(session)将使用什么样的UDP校验和策略。这可能既没关掉UDPchecksumming完全,或者使用UDP轻便在哪个检验数字盖住只数据报的部分。在每一个数据包进入到udp层,需要搜索这个链表,通过ip地址和端口号得到匹配结果,也就知道这个udp数据包是属于哪个应用(pcb)的。然后再调用这个pcb所对应的recv函数:pcb->recv(pcb->recv_arg,pcb,p,&iphdr->src,src);这里需要注意的是,udp已经是数据包的顶层了,它无法再把这个包递交给上层协议了,只能递交给应用程序。Udp_output:主要的实现函数是udp_sendto_if。当中有几段相对比较重要:1.分配空间:121./notenoughspacetoaddanUDPheadertofirstpbufingivenpchain?2.if(pbuf_header(p,UDP_HLEN)){3./allocateheaderinaseparatenewpbuf4.q=pbuf_alloc(PBUF_IP,UDP_HLEN,PBUF_RAM);5./newheaderpbufcouldnotbeallocated?6.if(q==NULL){7.LWIP_DEBUGF(UDP_DEBUGLWIP_DBG_TRACELWIP_DBG_LEVEL_SERIOUS,("udp_send:couldnotallocateheader\\n"));8.returnERR_MEM;9.}10./chainheaderqinfrontofgivenpbufp11.pbuf_chain(q,p);12./firstpbufqpointstoheaderpbuf13.LWIP_DEBUGF(UDP_DEBUG,14.("udp_send:addedheaderpbuf%pbeforegivenpbuf%p\\n",(void)q,(void)p));15.}else{16./addingspaceforheaderwithinpsucceeded17./firstpbufqequalsgivenpbuf18.q=p;19.LWIP_DEBUGF(UDP_DEBUG,("udp_send:addedheaderingivenpbuf%p\\n",(void)p));20.}接着还是填充udp数据首部,然后调用ip层的output函数ip_output_ifLwIP源码分析-6本帖最后由ConanDolye于2011-6-1709:27编辑TCP层:看了这么久,终于到tcp层了,换句话说就是进入主战场了,兴奋啊,哈哈。回顾一下tcp的特性,就当重温comer的第一卷:1.滑动窗口的概念:Tcp是通过正面确认和重传技术来保证可靠性的,但是如果简单的使用正面确认的技术将极大的浪费带宽,因为它在收到前一个分组的确认信息前必须推迟下一个分组的传送。13由此诞生了一种更为复杂的技术,在保证可靠性的同时能充分利用带宽——滑动窗口。(其实就是批量传输的概念,当滑动窗口的长度为1时就是简单的正面确认)。滑动窗口把整个序列分成三部分:左边的是发送了并且被确认的分组,窗口右边是还没发送的分组,窗口内部是待确认的分组,窗口内部又分成已经发送待确认的,和未发送但将立即发送。因为tcp是双工的,上面仅仅讲了发送,接受也有相应的滑动窗口,不过相对简单点。可参加协议卷2:p648.Tcp报文头部的代码比特位(6bit,也有文档称之为flag标志位),有6种:A.URGurgentpointer紧急指针B.ADKacknowledgenumber确认号C.PSHpush推送操作D.RSTresetconnection复位连接E.SYNsynchronizesequencenumber同步序列号F.FINendofdata发送方字节流已发完这里要注意几点,当建立一个新的连接时,SYN标志才会变1.而由于发送ACK无需任何代价,因为32bit的确认序列和ACK标志一样,总是TCP首部的一部分,因此在建立连接之后,这个字段(ACK和确认序列号)总是被设置之前总是看comer的那本用tcp/ip进行网际互联,这本书初学者看很好,但是想深入一点的话就觉得太简单了点,拿了fp的tcp/ip详解卷1:协议,觉得就讲的很好,所以建议对tcp/ip有一定基础的还是看tcp/ip详解比较好,而且lwip的代码就是根据这本书来写的,在tcp这部分的代码中有tcp_pcb的state,lwip中的state的状态机都是和卷1中182一模一样。看了书中关于状态机的这张表,就能很好的理解lwip中tcp_input->tcp_process中的代码了。2.Nagle算法Nagle算法是以他的发明人JohnNagle的名字命名的,它用于自动连接许多的小缓冲器消息;这一过程(称为nagling)通过减少必须发送包的个数来增加网络软件系统的效率。Nagle算法于1984年定义为福特航空和通信公司IP/TCP拥塞控制方法,这是福特经营的最早的专用TCP/IP网络减少拥塞控制,从那以后这一方法得到了广泛应用。Nagle的文档里定义了处理他所谓的小包问题的方法,这种问题指的是应用程序一次产生一字节数据,这样会导致网络由于太多的包而过载(一个常见的情况是发送端的"愚笨窗口综合症(SillyWindwSyndrome)")。从键盘输入的一个字符,占用一个字节,可能在传输上造成41字节的包,其中包括1字节的有用信息和40字节的标题数据。这种情况转变成了4000%的消耗,这样的情况对于轻负载的网络来说还是可以接受的,但是重负载的福特网络就受不了了,它没有必要在经过节点和网关的时候重发,导致包丢失和妨碍传输速度。吞吐量可能会妨碍甚至在一定程度上会导致连接失败。Nagle的14算法通常会在TCP程序里添加两行代码,在未确认数据发送的时候让发送器把数据送到缓存里。任何数据随后继续直到得到明显的数据确认或者直到攒到了一定数量的数据了再发包。尽管Nagle的算法解决的问题只是局限于福特网络,然而同样的问题也可能出现在ARPANet。这种方法在包括因特网在内的整个网络里得到了推广,成为了默认的执行方式,尽管在高互动环境下有些时候是不必要的,例如在客户/服务器情形下。在这种情况下,nagling可以通过使用TCP_NODELAY插座选项关闭。Lwip对nagle算法的解释如下:尽量将用户的数据合成一个数据包发送。只有在以下情况下,会立即发送:a.在本连接上没有已经发送了,但未被确认的数据。b.用户定义了nodelay标志位或者infr标志位(快速重传),c.Pcb连接上存在超过1个的未发送数据d.Pcb连接的未发送数据的长度超过mss(就是TCP数据包每次能够传输的最大数据分段)首先我们来看一下讲解lwip第一节中的流程图:可以很明显的看到tcp在整个lwip中占的部分是非常大的,在较老的版本中几乎占到了50%左右的代码量,在1.3.2中增加了不少其他的控制协议,但是即使这样大概也有30%左右。先来看一下lwip的文件组织目录:/core/tcp.c:tcp协议的普通通用函数,比如制造数据结构以及tcptimer的一些函数;/core/tcp_in.c:tcp层的输入处理,从上图中我们也可以看到具体的流程为:(ip_input()->)tcp_input()->tcp_process()->tcp_receive()(->application)./core/tcp_out.c:tcp层的输出处理,具体的流程为:tcp_write()->tcp_enqueue()->tcp_output->ip_output_if()理解tcp_process下面这张状态图非常重要:15状态:描述CLOSED:无连接是活动的或正在进行LISTEN:服务器在等待进入呼叫SYN_RECV:一个连接请求已经到达,等待确认SYN_SENT:应用已经开始,打开一个连接ESTABLISHED:正常数据传输状态FIN_WAIT1:应用说它已经完成FIN_WAIT2:另一边已同意释放ITMED_WAIT:等待所有分组死掉CLOSING:两边同时尝试关闭TIME_WAIT:另一边已初始化一个释放LAST_ACK:等待所有分组死掉看了tcpip详解后终于有点眉目了,我是从tcp_input入手的,但是刚好这部分代码是tcp中最复杂的一部分,像详解卷二中花了近100页来讲述但是对tcp_output啥都没提,可见一斑了。Tcp_input函数进来的时候做一些对数据首部的处理之后会去寻找一个合适的接口(和目的相同的ip和端口),和udp不同的是,tcp的pcb不像udp那么简单只有一个列表,tcp协议中建立了三个pcb的列表,分别为active,time_wait,listen16Active是最最常见的pcb链表,这个链表中的所有pcb已经处于能够正常接收和发送数据的状态了。言下之意下面两种状态都不是在正常接收或发送数据的状态。Time_wait状态时指tcp关闭一个连接之后会进入的状态,它在这个状态停留的时间为最大报文段生存时间(MSL)的两倍,用来区分新旧连接。关于time_wait队列的pcb的处理在tcp_timewait_input函数中解释了,在代码中队接受包的类型分成下面几类:A.TCP_RST直接返回B.Tcp_syn:这里为什么同步序列号是在范围内反而是一个error没搞明白?C.TCP_FIN:重新启动定时器对于listen状态的pcb,即等待syn被动打开,在服务器端用的比较多。可以参见上面的状态机图,listen状态只有收到syn才会进入SYN_rcv状态,因此相应代码被分为两种状态:A.FLAGS==TCP_ACK发送tcp_rst。B.FLAGS==TCP_SYN被动打开成功,则先需要建立一个新的pcb(调用tcp_alloc函数),为这个新建立的pcb填充成员。将这个pcb加入到active队列中。调用tcp_enqueue回应带有SYN,ACK标志的数据包。对于tcp_input函数的接下来的处于只是针对active的pcb的,因为两外两种状态的pcb在他们本身阶段已经返回了。Tcp_process基本就是对状态机图的代码诠释,具体参考我对lwip1.3.2的代码注释。这里面有一点需要注意,比如在SYN_RCVD的case中,这里面不仅仅调用了pcb自带的accept函数,还调用了tcp层自带的接收函数tcp_receive。就在我们第一篇综述中的那张图所示,上层和协议层的交互有两种方式,一种是应用程序可以在协议层进程中实现(即利用lwip自己提供的一套内部回调函数来通信),还有一种是应用程序和协议层通过邮箱等通信方式,因此代码中实现了两种方式。1.TCP_EVENT_ACCEPT(pcb,ERR_OK,err);2.if(err!=ERR_OK){3./Iftheacceptfunctionreturnswithanerror,weaborttheconnection.4.tcp_abort(pcb);5.returnERR_ABRT;6.}7.old_cwnd=pcb->cwnd;8./IftherewasanydatacontainedwithinthisACK,9.we\'dbetterpassitontotheapplicationaswell.10.tcp_receive(pcb);复制代码然后在tcp_process中调用tcp_receive函数。我们的流程是tcp_write->tcp_enqueue->tcp_output.171.tcp_write函数这个函数很简单,首先判断此时的pcb是否进入了可发送数据的状态,这些状态有ESTABLISHED,CLOSE_WAIT,SYN_SENT,SYN_RECD,(还有一些在状态机里面见到的状态,如LISTEN,FIN_WAIT1,FIN_WAIT2,CLOSED,CLOSING等则要么处于连接还未建立,要么是连接已关闭的状态,顶多再能发个ack包,不能再发数据了)如果是处于这些有效状态,则调用tcp_enqueue函数。2.tcp_enqueue函数tcp_enqueue通过把上层需要发送的数据包放在队列中,最后一起调用tcp_output来提高效率。看一下参数:tcp_enqueue(structtcp_pcbpcb,voidarg,u16_tlen,u8_tflags,u8_tapiflags,u8_toptflags)pcb:当前连接的pcb,arg:需要发送的数据,len:数据长度,flags:tcp首部的标志位。apiflags:TCP_WRITE_FLAG_COPY(说明空间需要分配并且拷贝至pbuf,否则则说明数据来自静态的存储器,比如rom,不需要拷贝)TCP_WRITE_FLAG_MORE。看代码流程:A.首先保存一些变量,比如此次传输数据的长度,要传输的数据的地址B.将所要传输的数据切割成一个个tcp_seg结构体,最大长度不超过一个mss,如果小于就是一个tcp_seg。很奇怪,第一个seg是存放在queue指针的队列上,其余的是存放在useg指针的队列上,并且useg始终指向最后一个seg结构体。C.完成了数据切割,我们现在需要把这些seg加入到pcb->unsend队列中。但是这段代码很奇怪,不知道是我看错了还是有bug?但理论上不会有这么明显的bug啊。3.tcp_output函数在tcp_enqueue函数中已经把我们要发送的数据放在了pcb的unsend链表上了。接下来我们就是要将这些数据发送出去。看流程:A.首先过滤flags标志位为立即响应并且没有携带数据的调用,直接tcp_send_empty_ack(pcb);(因为不是每个对tcp_output的调用都是经过tcp_enqueue)B.利用while循环对unsend链表上的seg一个个发送或跳过。a)跳过:对每个seg包会首先用nagle算法做一下检测,如果满足nagle条件,则会跳过这个数据包不做任何操作,留置合并一起发送。具体的条件可参考tcp概念部分的文章。b)发送:对于一般的seg包,则先置ack标志位,然后调用tcp_output_segment(seg,pcb);发送。4.关于tcp_output中的tcp_send_empty_ack(pcb);a)这里面的操作比较简单,主要是建立pbuf,然后建立tcp的首部与pbuf的联系,tcphdr=p->payload,然后填充tcphdr,传递给ip层。(调用ip_output函数)5.关于tcp_output中的tcp_output_segment(seg,pcb);a)同tcp_send_empty_ack(pcb);类似,不是很复杂。18',)
提供Lwip,lwip会员下载,编号:1700774020,格式为 docx,文件大小为18页,请使用软件:wps,office word 进行编辑,PPT模板中文字,图片,动画效果均可修改,PPT模板下载后图片无水印,更多精品PPT素材下载尽在某某PPT网。所有作品均是用户自行上传分享并拥有版权或使用权,仅供网友学习交流,未经上传用户书面授权,请勿作他用。若您的权利被侵害,请联系963098962@qq.com进行删除处理。

 下载
下载 下载
下载 下载
下载 下载
下载 下载
下载 下载
下载 下载
下载 下载
下载 下载
下载 下载
下载